Llama 3.3 on vLLM with Speculative Decoding
You can now double the tokens/s output speed with speculative decoding in vLLM. However, it is currently incompatible with JSON output mode.
📝 In Short
Use this:
python3 -m vllm.entrypoints.openai.api_server \
--model nm-testing/Llama-3.3-70B-Instruct-FP8-dynamic \
--speculative-model neuralmagic/Llama-3.2-3B-Instruct-FP8-dynamic \
--num-speculative-tokens 5
The tokens/s increased from ~30 to ~60 on an H100 when I benchmarked.
However response_format: json_object is currently incompatible: https://github.com/vllm-project/vllm/issues/9423
🆕 Speculative Decoding - New vLLM Feature
Speculative decoding has ish arrived in vLLM: https://docs.vllm.ai/en/latest/usage/spec_decode.html
The feature can already be used, but they warn that it is a work in progress.
Basically, a smaller model is used to generate tokens. The larger model validates these tokens, which is a faster operation, and will only generate tokens itself if the smaller model fails to produce the correct tokens.
Let's take it for a spin!
💻 Testing Setup on Vast.AI
😢 I don't own an H100. Neither do you (probably).
🤝 LUCKILY: we can both rent them on https://vast.ai/ for experimentation.
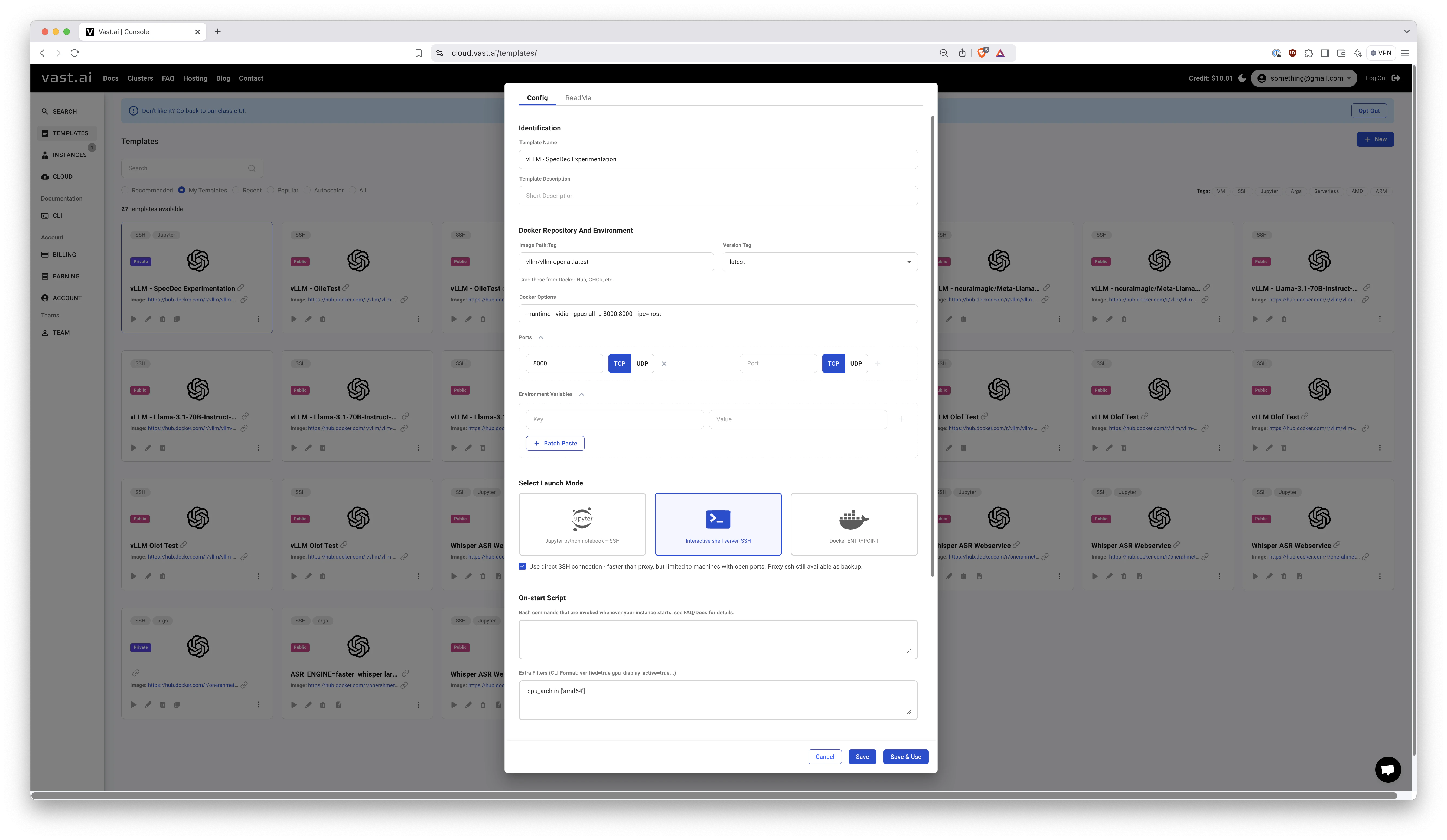
Here's the template data that I used in my experiments:
- Image Path:Tag:
vllm/vllm-openai:latest - Docker Options:
--runtime nvidia --gpus all -p 8000:8000 --ipc=host - Select Launch Mode:
Interactive shell server, SSH - Extra Filters:
cpu_arch in ['amd64'] - Disk Space:
200GB
Notably, I left the On-start Script empty. This is actually really convenient when experimenting. Instead just SSH into the machine and run the commands. You can then use CTRL+C to stop the vLLM server and change arguments easily. The machine IP and PORT will remain the same and models will remain cached on disk etc.
Here's a screenshot of what that template looks like:
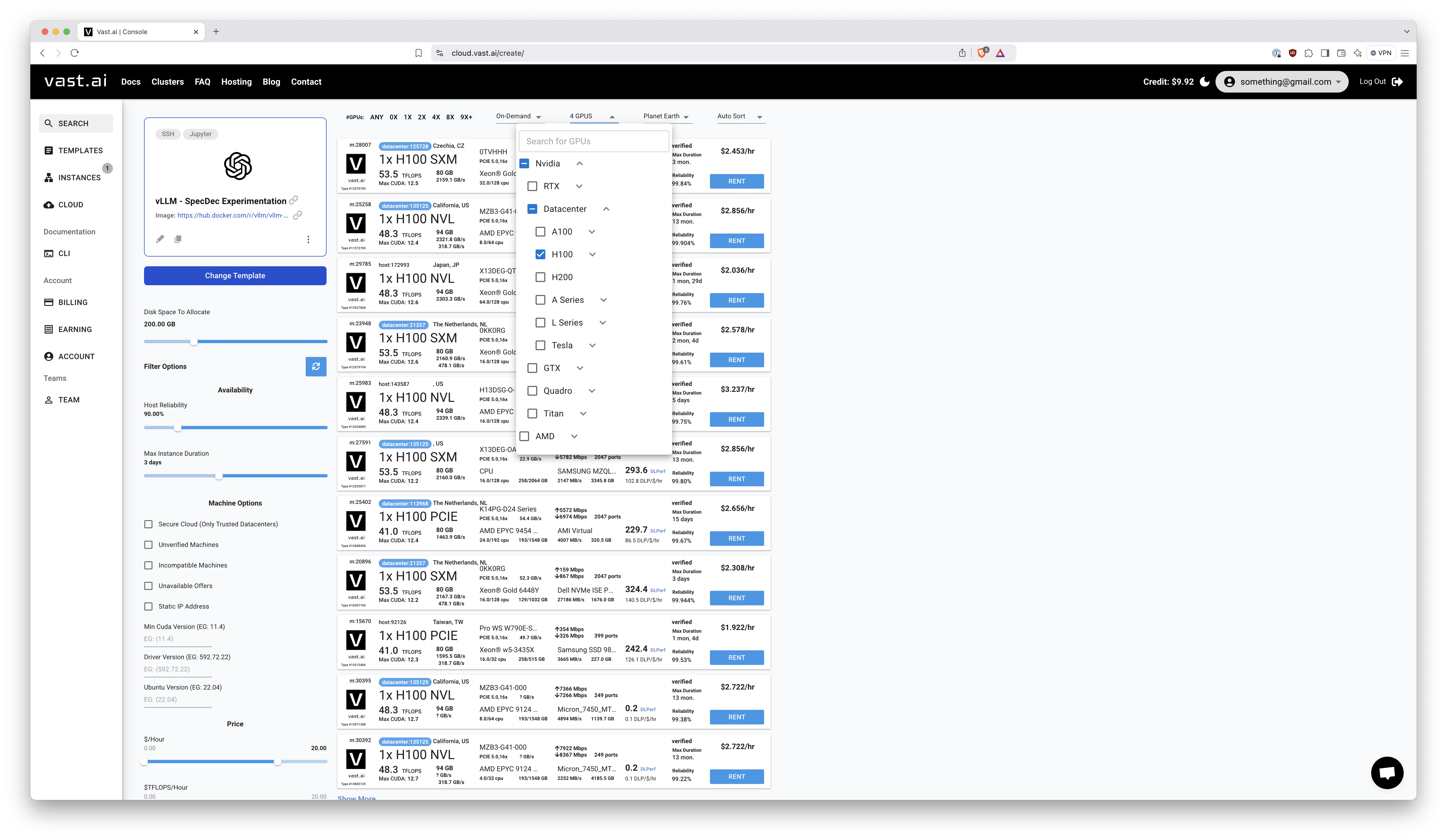
Next, find yourself some machine with a single H100 card and 96G VRAM:
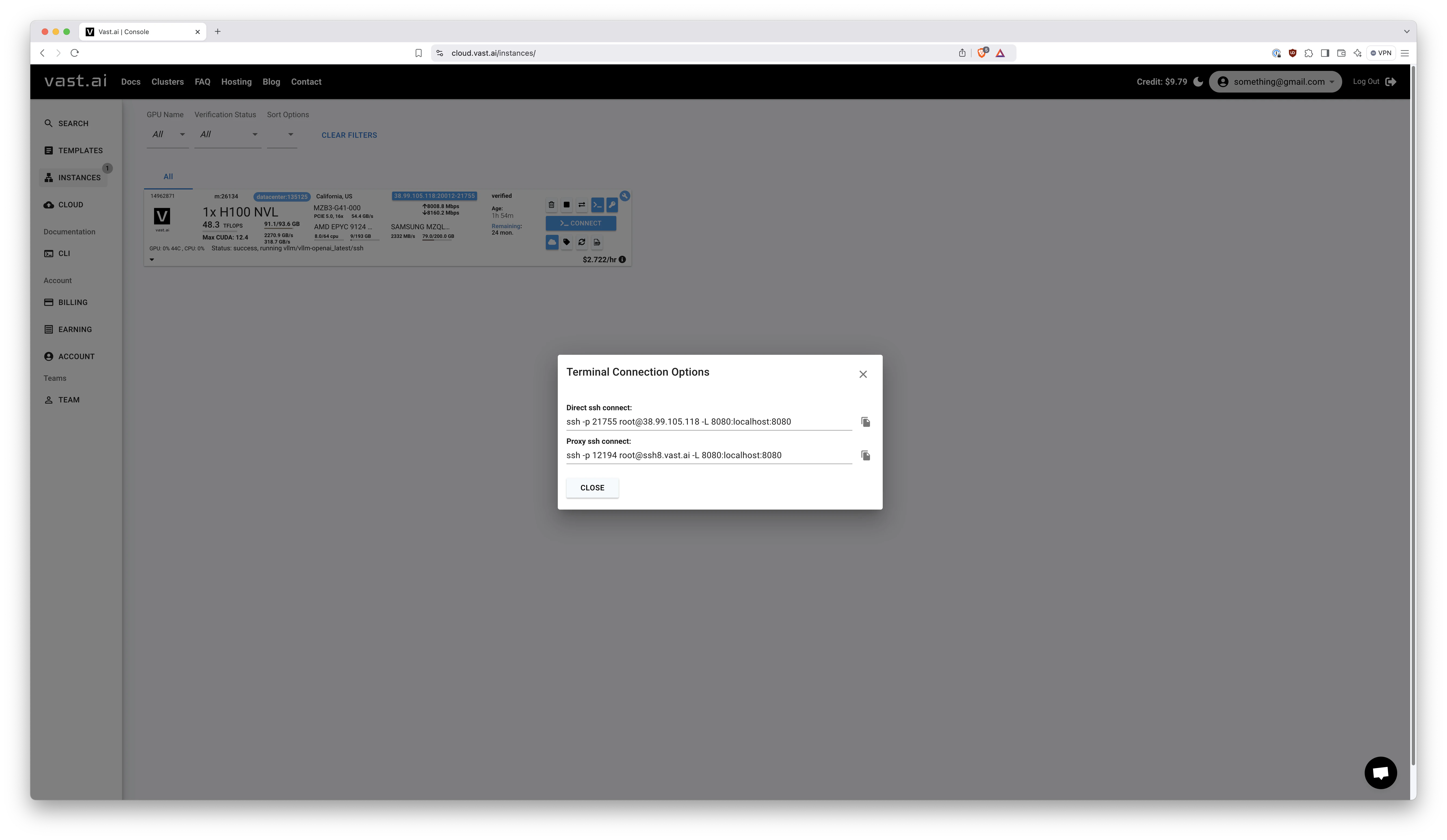
Click that blue > Connect button to obtain the SSH command:
You can now use a command like this to start vLLM:
python3 -m vllm.entrypoints.openai.api_server \
--api-key abc6356fce95ebb702f7 \
--max-model-len 8192 \
--model nm-testing/Llama-3.3-70B-Instruct-FP8-dynamic
Explanation:
--api-key abc6356fce95ebb702f7This adds basic security to the OpenAI compatible API.--max-model-len 8192Enforces a smaller maximum context length so that it fits in H100 VRAM.--model nm-testing/Llama-3.3-70B-Instruct-FP8-dynamicAn experimental NeuralMagic FP8 model for Llama 3.3.
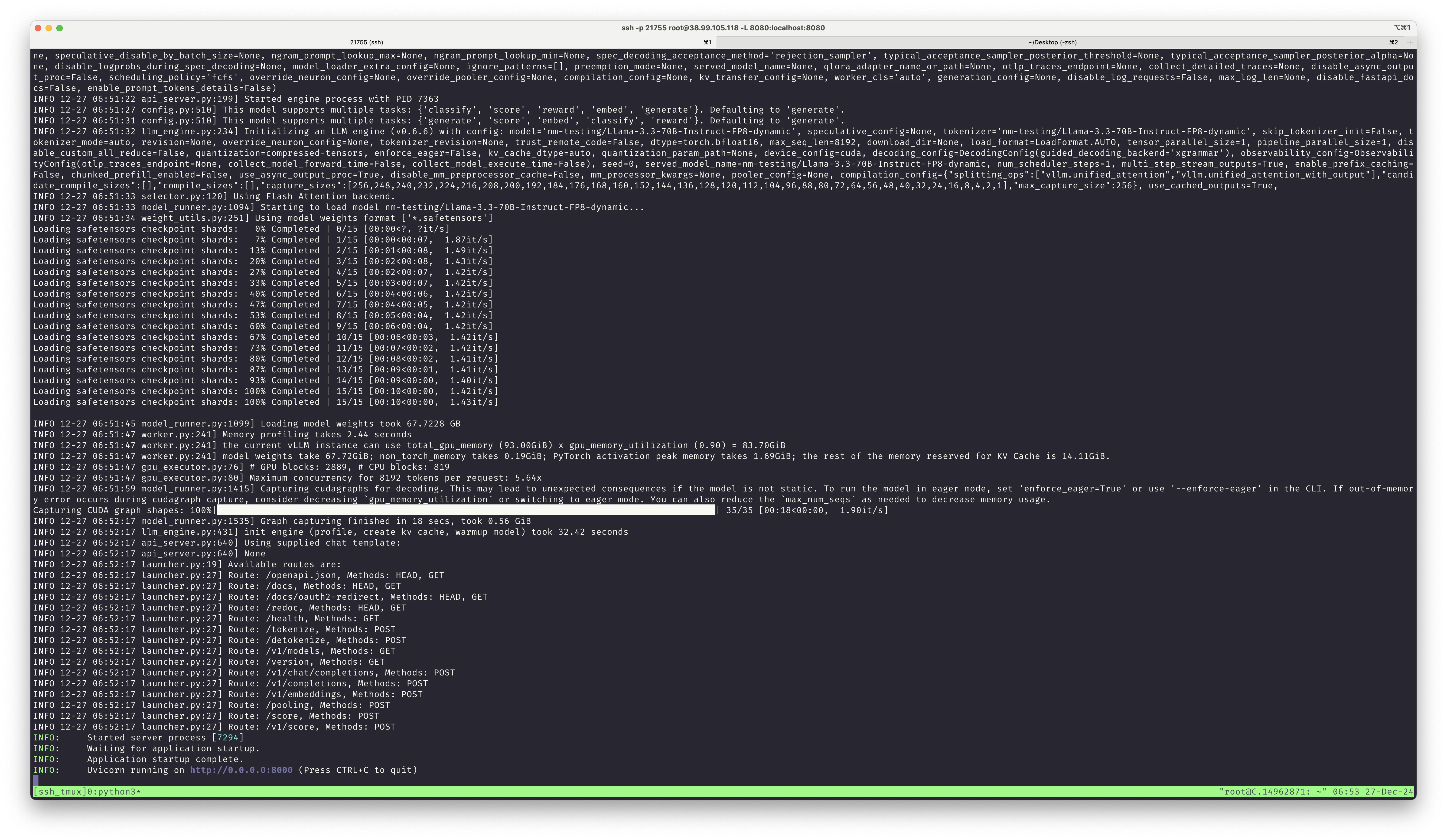
It will take a while to download the model and get started. You'll know it is fully operational when you see:
INFO: Started server process [7294]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
Like at the bottom of this screenshot:
You can then use a curl command like this to test it:
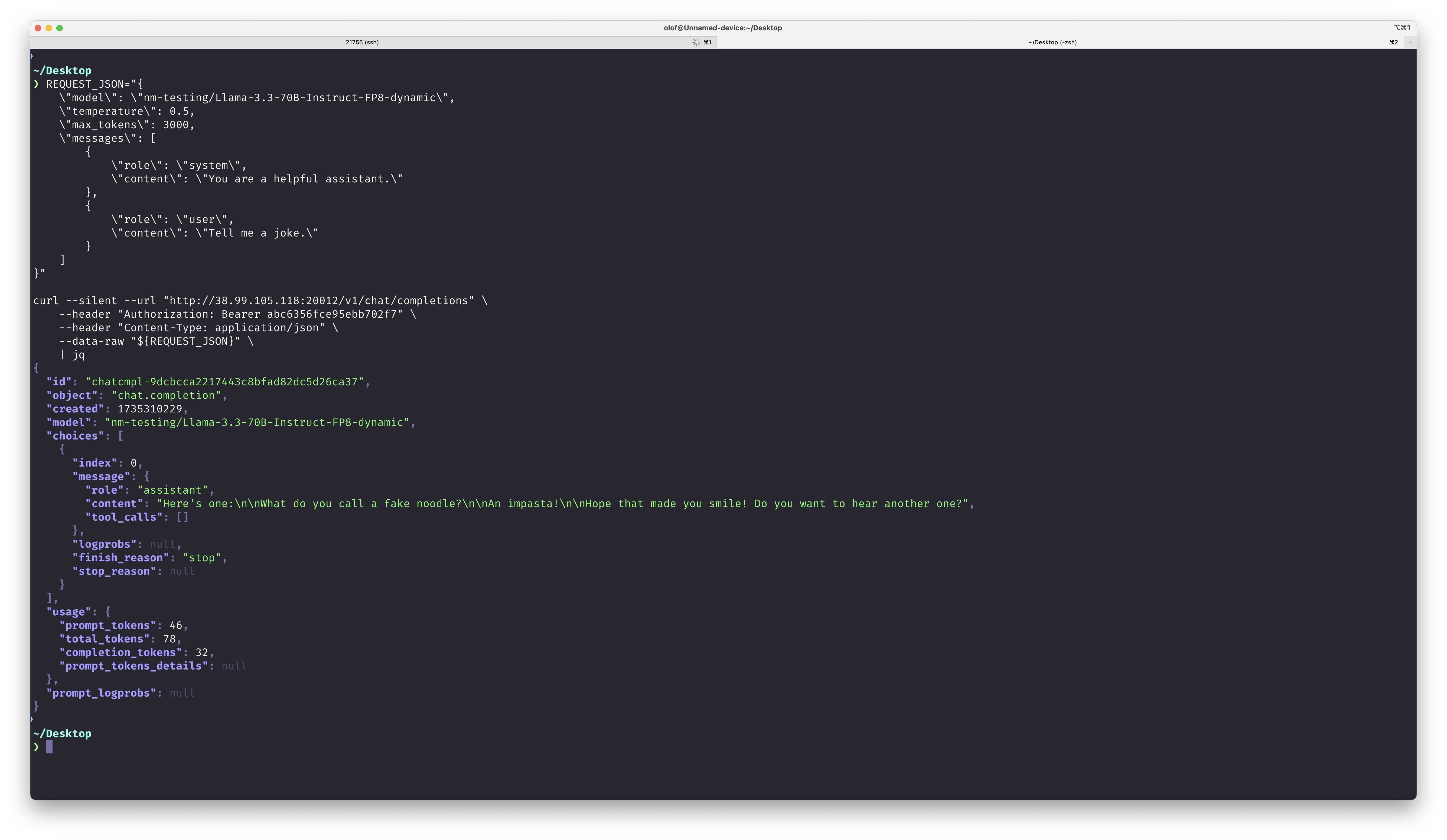
REQUEST_JSON="{
\"model\": \"nm-testing/Llama-3.3-70B-Instruct-FP8-dynamic\",
\"temperature\": 0.5,
\"max_tokens\": 3000,
\"messages\": [
{
\"role\": \"system\",
\"content\": \"You are a helpful assistant.\"
},
{
\"role\": \"user\",
\"content\": \"Tell me a joke.\"
}
]
}"
curl --silent --url "http://38.99.105.118:20012/v1/chat/completions" \
--header "Authorization: Bearer abc6356fce95ebb702f7" \
--header "Content-Type: application/json" \
--data-raw "${REQUEST_JSON}" \
| jq
⚠️ WARNING: Plain un-encrypted HTTP. You'll need something better for your production workloads. This is just for testing!
🤡 You'll get a response like this:
🧪 Adding SpecDec
🏎️ Time to add speculative decoding!
- Main Model: https://huggingface.co/nm-testing/Llama-3.3-70B-Instruct-FP8-dynamic
(Beta release from NeuralMagic of Llama 3.3 70B FP8) - Small Model: https://huggingface.co/neuralmagic/Llama-3.2-3B-Instruct-FP8-dynamic
(Stable release from NeuralMagic of Llama 3.2 3B FP8)
The new command looks like this:
python3 -m vllm.entrypoints.openai.api_server \
--api-key abc6356fce95ebb702f7 \
--max-model-len 8192 \
--model nm-testing/Llama-3.3-70B-Instruct-FP8-dynamic \
--speculative-model neuralmagic/Llama-3.2-3B-Instruct-FP8-dynamic \
--num-speculative-tokens 5
So, we just added 2 args at the end:
--speculative-model neuralmagic/Llama-3.2-3B-Instruct-FP8-dynamicThe smaller model to use for speculation.--num-speculative-tokens 5Speculate 5 tokens at a time.
Once up and running again you can run that curl command again to test.
Keep an eye out for the Speculative metrics:
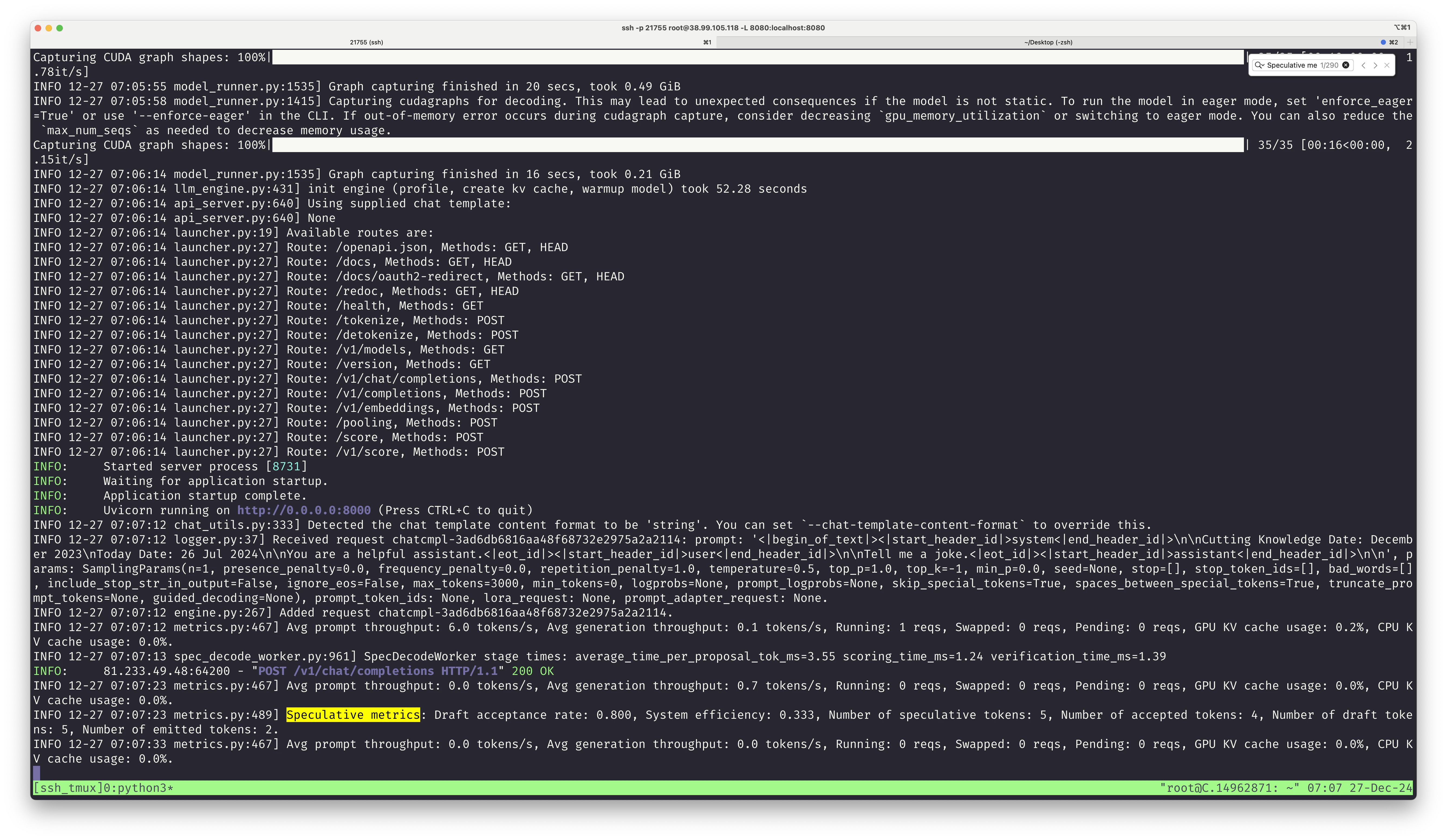
Speculative metrics: Draft acceptance rate: 0.800, System efficiency: 0.333, Number of speculative tokens: 5, Number of accepted tokens: 4, Number of draft tokens: 5, Number of emitted tokens: 2.
Neat! This means 80% of the tokens produced by the smaller model matched the larger model! In practice a x2 performance boost according to my benchmarks.
🧪 Benchmarking and Other Speculation Configurations
I benchmarked with ~20 customn prompts in Swedish. The use case in those prompts were largely summarization (good use case for SpecDec).
The settings above were the best ones I managed to find for Llama 3.3 SpecDec.
I also tried these other speculation configurations:
--speculative-model shuyuej/Llama-3.2-3B-Instruct-GPTQDraft acceptance rate dropped from 80% to 74% with this 4-bit quant. The smaller model size did not make up for that. Performance was slightly worse in the end.--speculative-model ibm-fms/llama3-70b-acceleratorDraft acceptance rate dropped from 80% to 1%. This example from the docs did not work well at all.--speculative-model "[ngram]" --ngram-prompt-lookup-max 4Draft acceptance rate dropped from 80% to 46%. Faster than without speculation but slower than using neuralmagic/Llama-3.2-3B-Instruct-FP8-dynamic.
During my benchmarking I also found that response_format: json_object makes vLLM crash if SpecDec is enabled. I suspect this is the related issue: https://github.com/vllm-project/vllm/issues/9423
💡 Conclusions
💡 The performance increase from 30 to 60 tokens/s for Llama 3.3 70B on H100 with vLLM SpecDec (recent beta release) is going to be really meaningful for more than one reason:
🐌 30 tokens/s felt a bit slow and detrimental to UX in my opinion. With 60 tokens/s it actually feels usable. It is like this speed bump made it past an important boundary. Are you building something where the user has to wait? SpecDec in vLLM is probably going to be an enabler for you.
🤡 Elon Musk has bought all NVIDIA Blackwell production for the upcoming few months. This means most of us are stuck on H100 cards for a while longer. Fantastic that a software change can double the tokens/s output!
⏳ Once SpecDec in vLLM stabilizes (and response_format: json_object works again) the open source ecosystem will seem somewhat complete for those that want to abandon OpenAI GPT-4 and the US-owned cloud. The timeline looks like this:
- Llama 3.1 70B (Summer 2024): The first multilingual open model viable for weird languages such as Swedish was released. Not quite GPT-4o level though.
- Llama 3.3 70B (Winter 2024): Just as good as GPT-4o. Performance on par with Llama 3.1 405B but now fits on a single H100.
- vLLM SpecDec (Spring 2025): Performance becomes "good enough" on H100.
🌟 Looking forward to the open LLM ecosystem maturing even further next year. Will further software optimizations + Llama 4 make RTX 5090 32GB the "new H100 for inference" in 2025? Likely? Happy new year!